本文共 4461 字,大约阅读时间需要 14 分钟。
布局效果如图所示:
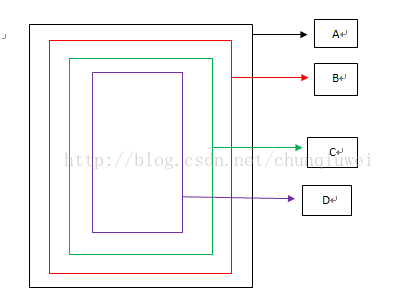
图1
参照上图先说说具体得到的结论:
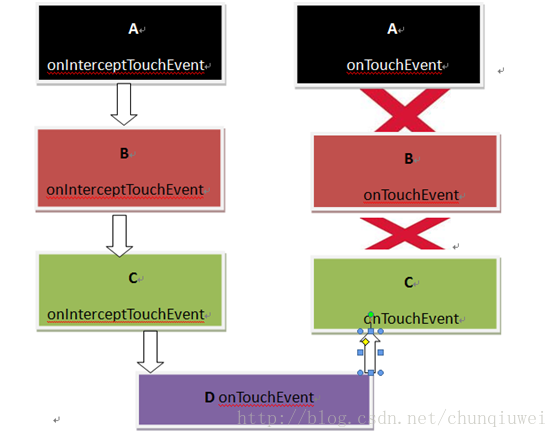
1) onInterceptTouchEvent负责对touch事件进行拦截,对于嵌套的view最先执行的是事件拦截方法的是最外层的那个view的onInterceptTouchEvent方法,然后依次执行子视图的onInterceptTouchEvent,然后在执行子视图的子视图的事件拦截方法(当然在这里假设所有嵌套视图的onInterceptTouchEvent都会得到执行,让每个视图的onInterceptTouchEvent返回false即可)。参照上图,所以onInterceptTouchEvent执行顺序就是A--->B--->C--->D.也就是由父视图到子视图传递。总之,事件拦截机制是由父视图开始发起对事件的拦截(出事了老子先上,儿子稍后)。参照上图当手指触摸事件时,父视图A首先发起对该起事件的拦截,如果A拦截失败,就交给它的子视图B进行拦截;如果B拦截失败就交给B的子视图C再进行拦截..直到某一子视图对该次事件拦截成功。
2)某一视图拦截事件成功与否的判断标识是onInterceptTouchEvent方法的返回值,当返回true的时候说明拦截成功,返回false的时候说明当前视图对事件拦截失败。
3)下面说说拦截成功的情况,假设C视图对当前touch事件拦截成功。拦截成功意味着此次事件不会再传递到D视图了。所以此时的D视图的onInterceptTouchEvent就得不到运行(事件没法到达了,还拦截谁呢?)。事件拦截成功后,紧接着就会对事件进行处理,处理的方法教给onTouchEvent方法处理。此时C视图拦截成功,那么紧接着就会执行C视图的onTouchEvent方法,这是不是就意味着当前touch事件是由C视图的onTouchEvent方法来处理的呢?这要由C视图的onTouchEvent方法的返回值来决定。当C视图的onTouchEvent返回true的时候,当前事件就由C全权处理,处理的当然是事件的各种action,什么MotionEvent.ACTION_MOVE,ACTION_UP都交给了C的onTouchEvent方法进行处理。所以此时就可以在C的onTouchEvent方法中进行switch(event.getAction)判断执行相关逻辑了。如果返回的false,说明C视图对此事件不做处理或者处理不了,怎么办呢?儿子不行老爸来,于是事件就交到了B视图的onTouchEvent方法中。同样B对此事件处理与否还是看B的onTouchEvent返回值,具体的解释就跟C一样了,不复多言。
4)在A B C D的onInterceptTouchEvent和onTouchEvent都返回false的情况下,方法执行的顺序依次为A.onInterceptTouchEvent-->B.onInterceptTouchEvent-->C.onInterceptTouchEvent-->D.touchEvent(最深的子视图没重写onInterceptTouchEvent)-->C.touchEvent-->B.touchEvent-->A.touchEvent.也就是说拦截事件是父视图优先有子视图进行拦截,处理事件是子视图优先父视图进行处理。
总结:onInterceptTouchEvent负责对事件进行拦截,拦截成功后交给最先遇到onTouchEvent返回true的那个view进行处理。
下面将要详细讲解上面结论是怎么得出的,准备分两部分进行一步步讲解。如果上面说的看明白的话,下面的内容就不要看了,因为会很啰嗦。
图1的布局代码如下所示:
-
<com.example.demo.AView xmlns:android="http://schemas.android.com/apk/res/android" -
xmlns:tools="http://schemas.android.com/tools" -
android:layout_width="match_parent" -
android:layout_height="match_parent" > -
<com.example.demo.BView -
android:layout_width="match_parent" -
android:layout_height="match_parent" > -
<com.example.demo.CView -
android:layout_width="match_parent" -
android:layout_height="match_parent" > -
<com.example.demo.DView -
android:layout_width="match_parent" -
android:layout_height="match_parent" -
android:text="测试demo" /> -
</com.example.demo.CView> -
</com.example.demo.BView> -
</com.example.demo.AView>
其中最后一个D是一个自定义的TextView,与A B C三个View的区别就是D只重写了onTouchEvent方法,A B C 这三个自定义控件还重写了onInterceptEvent方法。
D的代码如下,A B C代码基本上除了类名和输出log不一样外其余的都一样,所以为了减少这里只贴出其中的一个。
DView的代码:
-
public class DView extends TextView{ -
private static String tag = "D"; -
public DView(Context context, AttributeSet attrs, int defStyle) { -
super(context, attrs, defStyle); -
} -
public DView(Context context, AttributeSet attrs) { -
super(context, attrs); -
} -
public DView(Context context) { -
super(context); -
} -
@Override -
public boolean onTouchEvent(MotionEvent event) { -
Log.e(tag, "--onTouchEvent--D"); -
return false; -
} -
}
AView的代码和C D的整体差不多,就贴出来一个:
-
public class AView extends RelativeLayout{ -
private static String tag = "A"; -
public AView(Context context) { -
super(context); -
} -
public AView(Context context, AttributeSet attrs, int defStyle) { -
super(context, attrs, defStyle); -
} -
public AView(Context context, AttributeSet attrs) { -
super(context, attrs); -
} -
@Override -
public boolean onInterceptTouchEvent(MotionEvent ev) { -
Log.e(tag,"--onInterceptTouchEvent--A"); -
return false; -
} -
@Override -
public boolean onTouchEvent(MotionEvent event) { -
Log.e(tag,"--onTouchEvent---A" ); -
return false; -
} -
}
刚开始的时候重写的方法全部返回false运行点击的效果输出log为:

转换成效果图为:
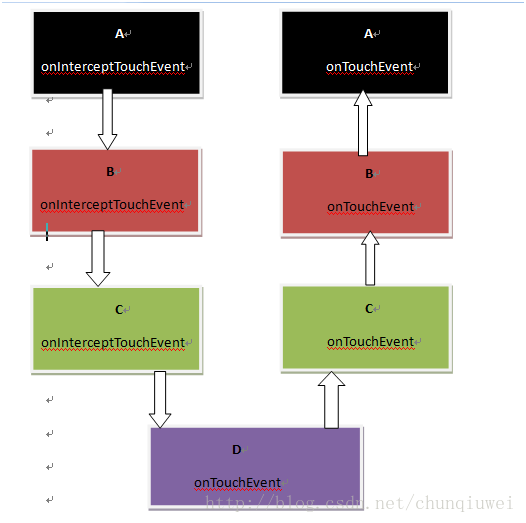
从此图可以看出,onInterceptTouchEvent事件的执行顺序是由父控件到子控件,并且优先于自己控件的onTouchEvent方法执行,onTouchEvent事件执行的顺序正好相反由子控件到父控件。注意由于此时都返回了false,是没有哪一个view来处理此次的touch事件的各个ACTION的,这也是为什么onTouchEvent为什么会一直传递到A的原因。所以ACTION_MOVE和ACTION_UP等事件得不到相应(处理),此种情况下即使你在D的onTouchEvent方法里面写了如下代码,也不会得到执行。
-
if(event.getAction()==MotionEvent.ACTION_MOVE){ -
Log.e(tag, "--onTouchEvent--*****"); -
}
1)如果A的InterceptTouchEvent返回了true,其余的仍然返回false,那么执行输出的log为:
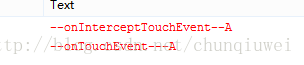
转换成效果图为:
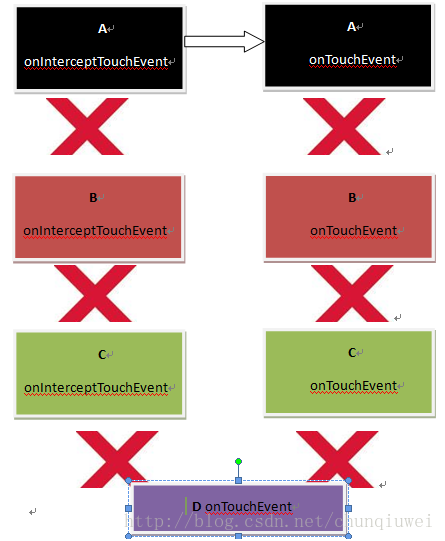
可以发现此时A拦截了此次Touch事件,事件不再向A的子控件B C D传递。此时所有的action事件比如手指移动事件ACTION_MOVE或者ACTION_UP事件啦等等事件都交给A的onTouchEvent方法去处理(当然这是在onTouchEvent方法返回true的情况下,如果返回false经过测试时不会相应这些action的)。B,C ,D控件是的事件处理拦截方法和事件处理方法是无法得到执行的。
2)只有B的onIntercepteTouchEvent事件返回了true的情况下,打印的log为

转换成效果图为:
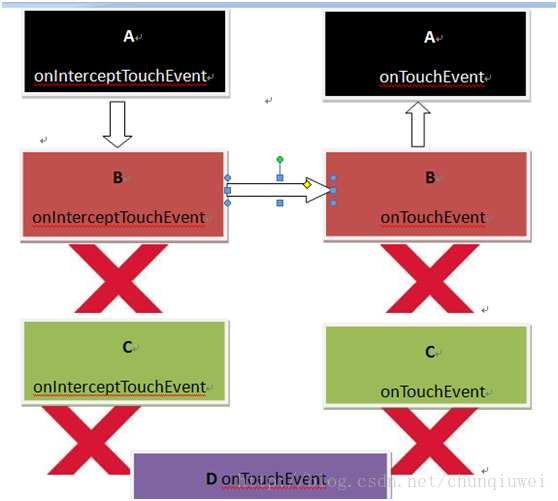
此时由B拦截了此次Touch事件,并不会向C D子控件传递;同样的由于onTouchEvent事件返回为false,所以此次事件的event.getAction()的各种action都不会得到处理。
4)同理可知,C控件的onIntercept方法返回了true的情况下,其余的仍然返回false的情况下,输出log为

转换成效果图为
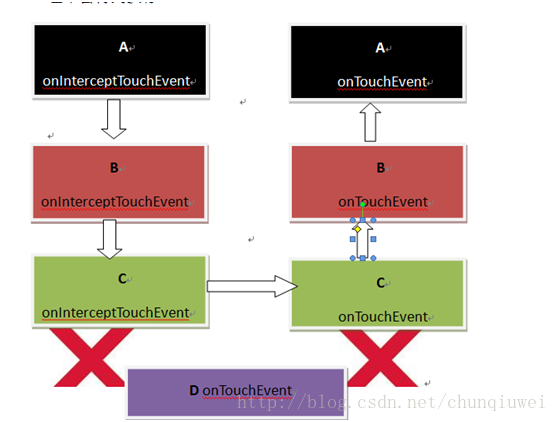
下面说说各个view的onTouchEvent返回true的情况
由于onTouchEvent事件是从子控件到父控件传递的,当D的onTouchEvent返回true的时候,经测试输出效果如下

转换成效果图为:
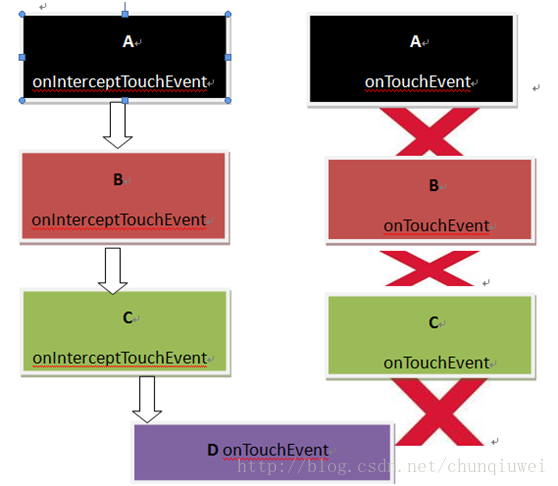
经过测试发现,此时D处理了此次Touch事件的各种action,C B D是的onTouchEvent的没有得到执行。
同理当C的onTouchEvent方法返回了true的时候,输出的log如下
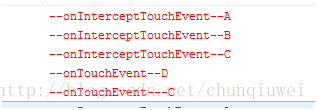
转换成效果图如下:
经过测试发现,其余情况一次类推,就不在啰嗦了。经过一步步的测试得出了文章开头的结文章有点啰嗦,希望可以对阅读此文的人有所帮助。